Operator Pattern além do K8s
Volta e meia eu fico muito aficionado por algum tema da computação. Às vezes é um assunto já batido, que encontro de monte por aí, mas geralmente é algo mais específico, que alguns conhecem e poucos usam.
O tema da vez foi o Incus, um sistema de virtualização e containers derivado do LXD, voltado para quem precisa de algo mais leve que uma VM, mas mais completo que um container tradicional.
E foi quando me convidaram para falar em uma apresentação que fiquei empolgado por dois motivos: primeiro, porque seria a minha primeira apresentação e já tinha um tempo que eu queria ver como me sairia em uma e, segundo, porque eu poderia falar sobre Incus e LXD.
Comecei a pensar em como abordar e percebi que poderia acabar trazendo apenas vários hands-on e conceitos de virtualização. Fiquei tentado a fazer uma linha quase histórica sobre virtualização e seus usos, mas me imaginei falando 40 minutos só disso… e talvez eu não fosse a melhor pessoa para esse tipo de narrativa (nem ficaria realmente feliz fazendo).
Então decidi retomar alguns tópicos que vinha pensando e conceitos que vi quando estive no MGC: daemon, o próprio Incus, Golang e… Operadores. Nesse momento, resolvi juntar tudo e focar em algo mais prático como um lab: explicar algo próximo do dia a dia do dev (talvez não de todos), mas ao mesmo tempo experimentar umas coisas.
E assim surgiu o tema: Operator Pattern além do K8s: IaC Reativa com Primitivos do Linux.
Mas para chegar no lab precisamos entender algumas coisas.
Mas afinal, o que são operadores?#
Para explicar isso, precisamos falar de quem está sempre atrelado a eles: o Kubernetes.
De forma simples, o K8s é um orquestrador de containers. Mas o que significa orquestrar? Nesse caso, é automatizar deploy, escalabilidade e gerenciamento de aplicações e resiliencia.
Simplista? Talvez. Então vamos um pouco mais fundo.
O K8s foi pensado para ambientes grandes, com muitos componentes, o famoso mundo de microserviços. Ele lida muito bem com sistemas distribuídos, e por isso exige uma arquitetura distribuída (embora haja controvérsias).
No coração dessa arquitetura, temos duas entidades principais:
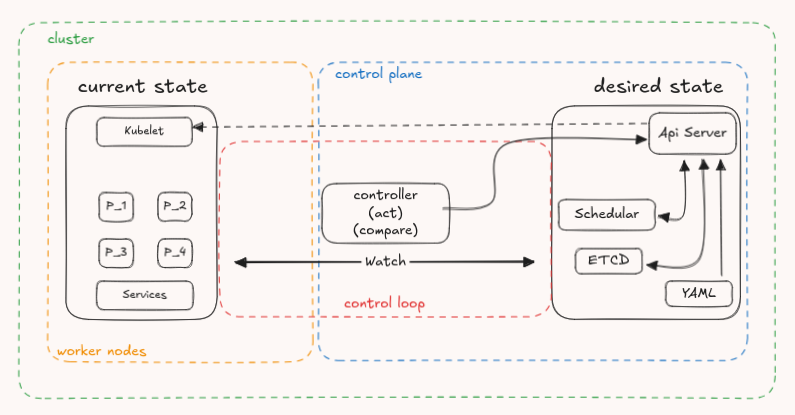
- Control Plane: basicamente nele ficam as orquestrações. Ele orquestra as requisições pelo API Server, guarda estados no ETCD (banco NoSQL do K8s), agenda cada pod com o Schedular e mantém monitoramento constante do estado do sistema, garantindo resiliência com os Controllers.
- Worker Nodes: onde vivem os pods e onde a ação ocorre. Aqui temos o agente que executa as ações, quem gerencia a rede e o runtime dos containers. Um desses exemplos é o Kubelet.
Resumindo: quando você cria seu YAML, roda o kubemine start e depois apply nos manifestos se define um estado desejado para o cluster. O API Server recebe essa intenção, salva no ETCD e passa a ordem para o Scheduler decidir onde colocar cada recurso. Assim que o Schedular gera esse agendamento o Api Server ordena o Kubelet a trabalhar nos pods sendo criando, deletando e etc.
Mas focando nos Controllers que ficaram de fora desse fluxo, eles garantem que tudo fique no estado correto. Se um pod falha, o Controller que está monitorando avisa o Api Server para ele dar a ordem de criação (desde que isso esteja definido, claro).
Esse design todo tem um core quando falamos em resiliência (o trunfo do K8s): o Reconciliation Loop (esse nome o K8s deu) ou Control Loop (esse eu não sei quem deu, mas é mais velho). É nele que a mágica acontece. Observar o estado atual, comparar com o desejado e agir se necessário. Isso é exatamente o que os operadores fazem e isso fica dentro dos Controllers.
Operadores: o SRE codificado#
Operadores automatizam conhecimento específico de domínio. É como se um SRE experiente estivesse codificado em software, pronto para agir dentro do cluster.
Exemplo prático:
o K8s escala pods baseado em CPU e memória. Mas e se quisermos algo mais inteligente, como escalar com base no tamanho de uma fila de mensagens?
O operador interage com o API Server por meio de um CRD (Custom Resource Definition), que define um novo tipo de recurso. A partir da especificação YAML (define o estado desejado pelo usuário), o operador atua como um controller especializado: observa a fila, contabiliza mensagens e, quando necessário, aumenta ou reduz o número de pods.
Percebe o padrão? O operador replica o que um SRE faria manualmente: observar métricas específicas do domínio, tomar decisões inteligentes e age automaticamente.
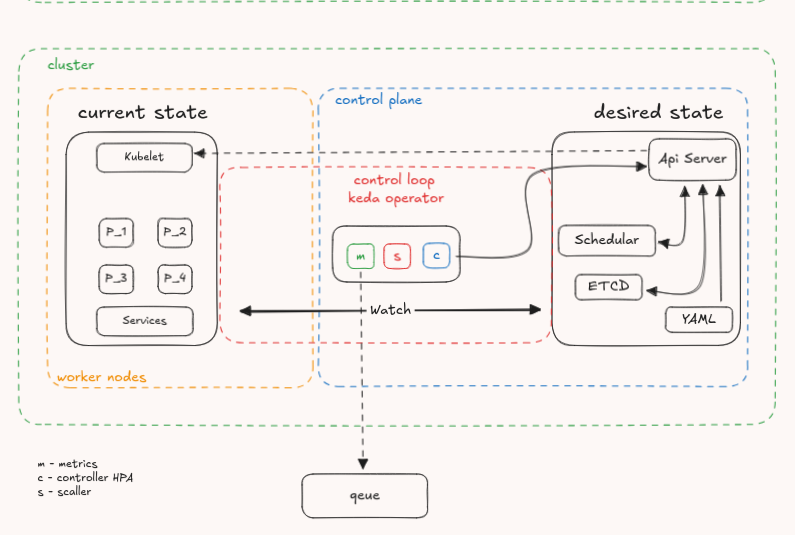
Aqui a gente consegue ver isso acontencendo, o controller no meio agindo como operador ele busca métricas de uma fila no Metrics faz a lógica de comparação no scaller já tomando a decisão de agir e com isso passa a vez para o Controller que é quem se comunica com o Api Server. Lindo de se ver
Mas… eu já vi isso antes#
Quando vi o K8s chamar isso de “Operator Pattern”, fiquei pensando em como eles foram geniais, fiquei impressionado, eles conseguiram dar nome e estrutura a algo que fazíamos há décadas de forma ad-hoc. Tipo eu pensei: eu já vi esse padrão antes.
E vocês também. Só que não necessariamente dentro do K8s.
Primeiro, entendendo no macro ou micro, não sei muito bem, tem essa imagem que eu criei apartir de uma ideia:
A ideia é simples demonstrar que o paralelo entre o K8s e maquinas de estado e tudo que tem entre eles. Foi uma adaptação de um tipo bem primitivo até chegar no K8s que conhecemos hoje.
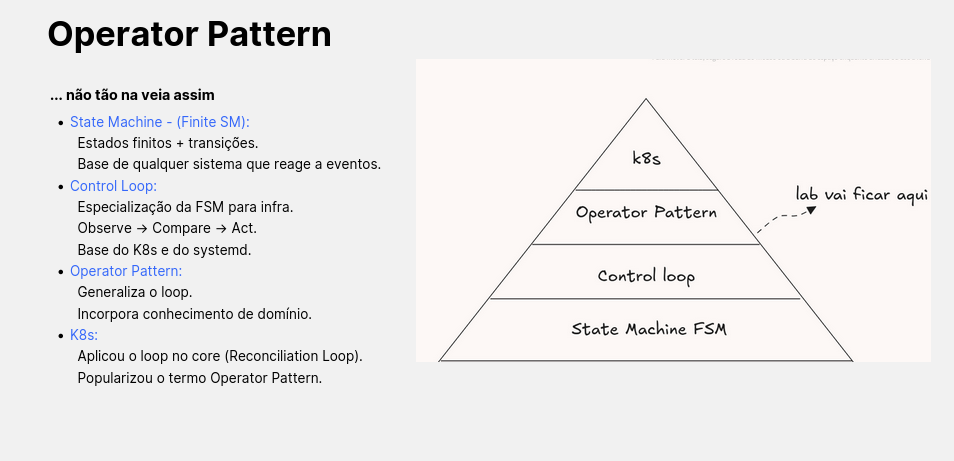
sim, peguei um slide da apresentação, pois só vi esse paralelo depois de escrever o roteiro e agora estou retocando para o texto
Na prática, estamos falando de reconciliação — o famoso “observe, compare e aplique”. Esse conceito existe há muito tempo:
- 1975–1990: Unix e Linux faziam isso com cron + shell scripts, trazendo um tom de reconciliação rudimentar:
observe = hora
compare = agenda
act = run script
- 2005–2010: ferramentas de config management, como Puppet fazem o mesmo com scripts manuais e seus manifestos:
observe = estado real da máquina
compare = manifesto
act = install
- 2010: surge o systemd (para alegria de muitos e tristeza de outros), com um control loop baseado em falha:
observe = daemon status
compare = unit file
act = restart service
- 2011–2014: o boom do IaC com Terraform, com control loop similar ao config management.
- 2014 – atual: K8s e operadores consolidam esse padrão. É o que vemos agora.
Provavelmente teve muitos outros que deixei de fora, vale a pesquisa!
Amarrando tudo#
Agora vamos trazer um pouco de contexto e base do padrão control loop em um Lab. Quero dizer, meu divertimento começa agora (na verdade já foi agora estou escrevendo o que também é divertido exceto que sou meio meh nisso).
A ideia: criar um lab para demonstrar um operador usando primitivos do Linux, um pouco de Go, Incus e entregar um HPA para containers Incus.
É isso mesmo. Bora ver um pouco.
Aliás, o código todo que usei nesse lab está disponível aqui: https://github.com/LucasRiboli/Forge-Operator-Lab
Primeiro passo acredito que seria clonar o repo:
git clone https://github.com/LucasRiboli/Forge-Operator-Lab.git
cd Forge-Operator-Lab
O próximo passo, seria entender primeiro o que eu fiz. Para isso, tem um desenho:
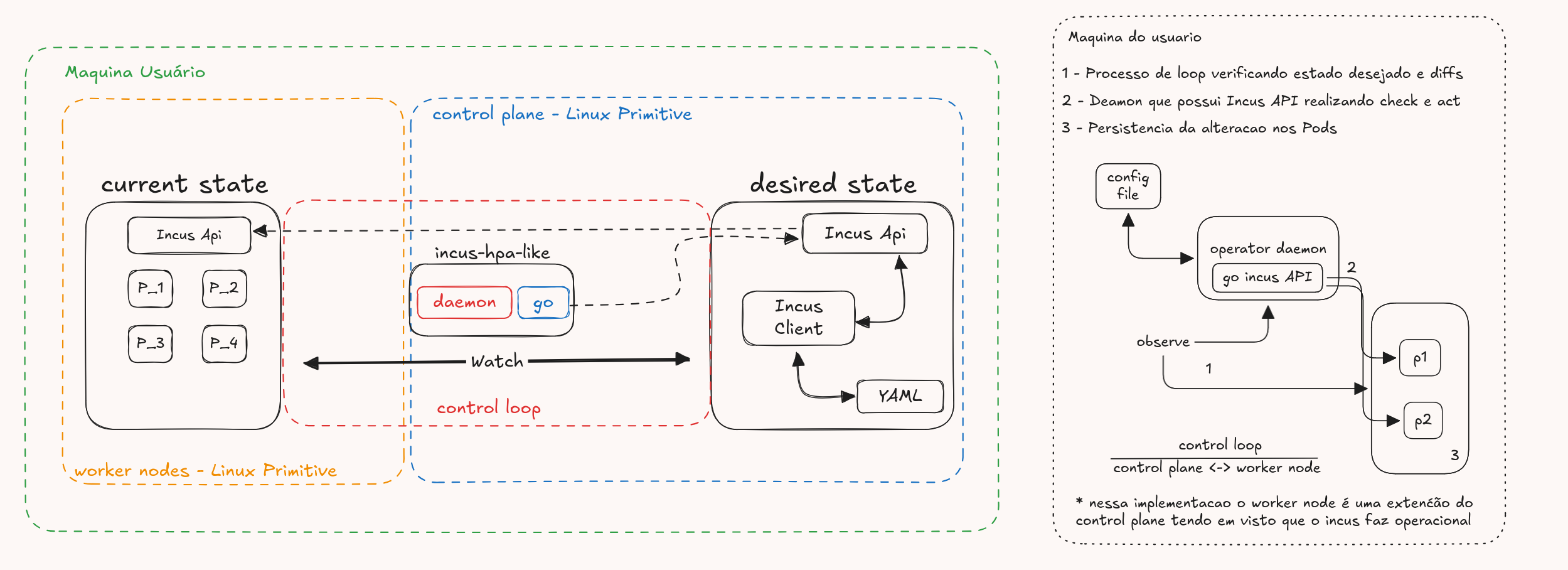 Aqui eu tentei trazer uma visão proxima a do K8s já que ele é nossa base, porém muita coisa foi abstraida.
Aqui eu tentei trazer uma visão proxima a do K8s já que ele é nossa base, porém muita coisa foi abstraida.
Vale entender também pela img da direita como é o fluxo, ja a imagem da esquerda ela é uma representação com as demais que fui trazendo, acredito que ajude também
OBS: Esse lab não é sobre substituir o Kubernetes (kkkk obvio né), mas sim mostrar como o operator pattern pode ser aplicado em qualquer infraestrutura, (com primitivos simples do Linux nesse caso). A ideia é abrir espaço para experimentos, forks e adaptações.
Ok, explicado isso vamos nos voltar para o código e ver o core do nosso control loop a func runHPALoop:
Por que ela é o core? Bom, porque nela está o processo do control loop inteiro::
observe:
for _, container := range hpaPods {
if container.State.Status == "Running" {
state, err := getInstanceState(container.Name)
if err != nil {
log.Printf("Erro ao capturar estado do pod %s: %v", container.Name, err)
continue
}
if state.Memory.Total > 0 {
porcentagemPod := (state.Memory.Usage * 100) / state.Memory.Total
sumMemory += porcentagemPod
runningPods++
log.Printf("Pod %s: %d%% memória utilizada", container.Name, porcentagemPod)
}
}
}
compare:
if totalMediaMemory >= int64(hpa.HPA.MemoryThreshold) {
if runningPods < int64(hpa.HPA.MaxPods) {...}
}
&
if totalMediaMemory < int64(hpa.HPA.MemoryThreshold)/2 {
if runningPods > int64(hpa.HPA.MinPods) {...}
}
act:
return createPod(name)
return deletePod(podToDelete)
Resumindo:
observe -> medir uso de memória dos pods
compare -> checar se está acima/abaixo do threshold
act -> criar ou apagar pods
Todos o resto do código basicamente é apoio/lógica ou o Incus executando alguma acao. Recomendo olharem e entenderem também.
Entendendo esse padrão em código, podemos avancar em como iniciar essa aplicação toda. Primeiro, instalar o Incus seguindo o passo a passo da documentação oficial (https://linuxcontainers.org/incus/docs/main/installing/)
Após fazer isso pode seguir gerando um executavel do nosso sistema:
go build -o operador cmd/main.go
e em seguida instale nosso daemon
sudo ./operador/install-daemon.sh
após isso crie um container com o nome pod dentro do incus e estresse ele para ver a magina acontecer
para isso pode rodar
sudo ./lab-init.sh
Basicamente, assim você teria seu HPA baseado em memória para o cluster Incus, com o daemon operador como base de controle e o código (que você pode ajustar) operando tudo.
Enfim, experimente alterar o estado desejado para desligar o container em vez de subir outro. O operador deve reagir e aplicar essa mudança. Essa é a mágica: você descreve o que quer, e o loop garante que se torne realidade
Por fim era isso, gostei mto de fazer esse estudo e esse lab para a apresentacao e transformar ele em texto e segue sendo bom criar labs e compartilhar.